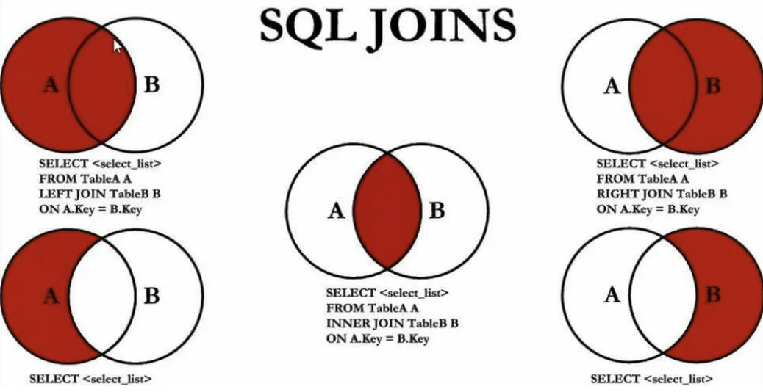
mysql之join left join踩坑记

背景:最近优化个线上导出的功能,本来测试环境没啥问题;一上线不行了,下载超时;然后一顿改,把代码实现的逻辑全扔sql里了,发现反而更快,啥查询字段里不要加函数,分批查询啥的;没有,就是简单粗暴能查出来就行;别的事又催的紧,那就先上去看看再说吧;这不一发上去发现,有些条件下的数据还能导出,有些条件下的数据还是不能导出还是超时;优化了个寂寞,哎。。。怀着不甘的心我本地造了几万的数据量,模拟下特定条件下的数据量,想着看看是不是数据量对查询计划有影响(实际大表数据量有50w+),所以有了这篇文章;
初始化工作建表
1 | 建表mother_t(id,name,batch_date) |
初始化数据
6.19日期下初始化5万条数据,6.20日期下初始化500条数据,6.21日期下初始化10条数据
1 | select ct.id from |
思考
其中mother_t 表和child\_t表是1对1关系;这里有个小插曲,之前child表关联mother表是left join关联,同事说一对一的改为join关联就好了,测试环境测了下发现left join 和join 查询出来的数据量不同,但是业务肯定是要业务主表有数据的,子表没数据也不能影响主表看数;因为这边数据质量一直都不算好,所以又改回了left join;并且查看了这两张表join 和left join 查询的执行计划发现一样,所以就没放在心上;*
哎,终究是出问题;那就看看问题实际出在哪里吧;完成上述基础事情,我迫不及待的打开数据;看了下执行计划,发现确实是一样的啊,没毛病啊…等等,不对,这里实际业务场景还有一张brother表(大概就是那么个意思,理解就行,这里不描述具体业务);其中mother作为主表,又存了brother表的主键;
所以改之前sql
1 | select m.id from mother_t m |
改之后sql
1 | select m.id from mother_t m |
难道这里,主表不同;join 和left join执行计划会变;我迫不及待的 调换了下主次表的顺序,再次比对其执行计划;发现果真有坑啊!!!
执行计划如下图

啊这,这和我想的不一样啊;一对1的关系,join 和left join应该没啥区别,性能没差才对啊;
然后,我问了波AI
1 | me:你是个java开发工程师,mysql在联表查询时遇到了个问题,现在有两张表 表A 表B |
加索引会怎么样?
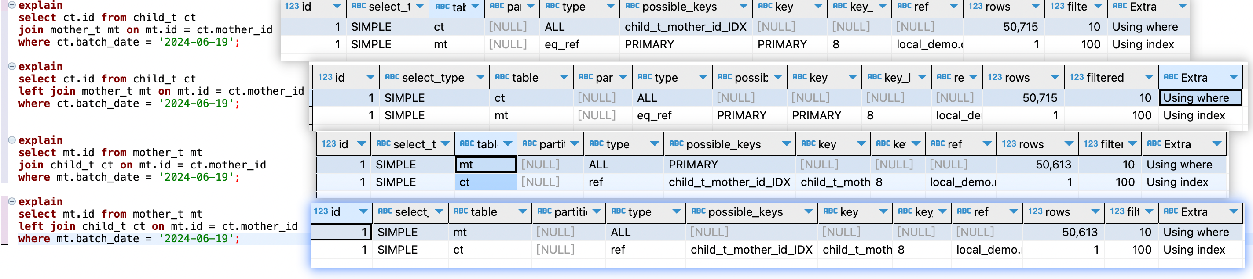
加了索引,发现不管哪张表做主表,只有join的关联条件才会走索引,left join 依然走全表扫描;好吧,我再次问了下ai
1 | me:添加了索引后,发现;A做主表是 join B_id 走了索引,left join B_id没有走索引,这是为何? |
总结
至此,我们总算明白了join 和left join带来的性能差异点在哪里,在实际的应用中如果能用join 就用join 必须用left join时最好保证,含有关联关系的表作为主表,多张表关联无法兼顾时可采用子查询的方式;实践出真知,奥利给!
- Title: mysql之join left join踩坑记
- Author: viEcho
- Created at : 2024-06-21 22:28:37
- Updated at : 2024-06-21 23:37:01
- Link: https://viecho.github.io/2024/0621/mysql-join-left-join.html
- License: This work is licensed under CC BY-NC-SA 4.0.